

Technical
Summary Module

The following diagram shows the main workflow of a text sent for summarization:
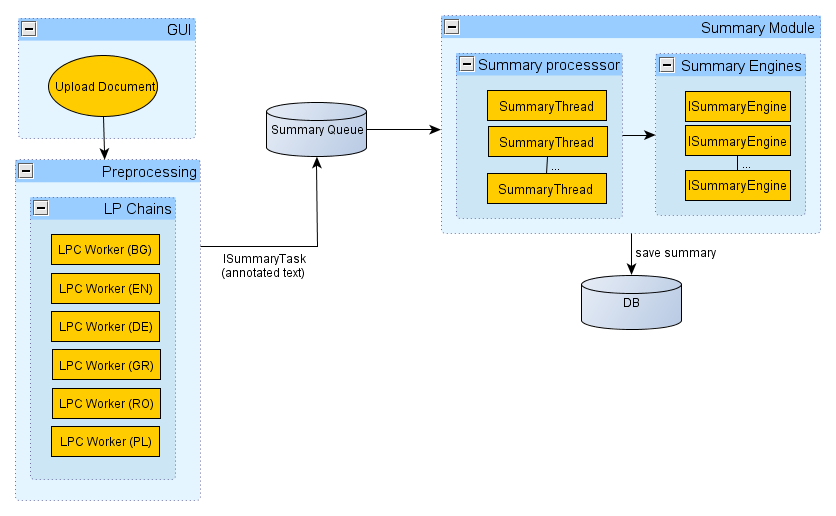
As a mandatory first step, all texts are processed by the LPC (Language Processing Chain) module. The LPC performs sentence splitting, tokenization, part of speech tagging, lemmatization, noun phrase extraction, and name entity recognition. The already annotated text is send as a serialized Java object (com.tetracom.atlas.tm.summary.api.ISummaryTask) to a summarization queue.
The plugin com.tetracom.atlas.tm.summary fetches summary tasks from the queue and sends them to the summarization engines.
The summarization engines are instances of com.tetracom.atlas.tm.summary.api.ISummaryEngine interface.
The plugin com.tetracom.atlas.tm.summary.uaic.shorttxt implements the summarization approach suitable for short texts. The module wraps the invocations to the UAIC.SummaryExtractor summarazition engine. The following diagram shows the operations performed by the module.

This UIMA engine performs anaphora resolution (AR), clause splitting (CS), discourse parsing (DP), and annotates the text with corresponding tags, which are later used during the summarization phase.
The summarization engine for longer texts is implemented in the com.tetracom.atlas.tm.summary.ie plugin. The algorithm estimates the importance of each sentence by using different heuristic rules such as boosting sentences where noun phrases or named entities are introduced for the first time. Optionally the module could include and use coreference resolution information to improve sentence estimates.
Two coreference resolution plugins are available. The plugin com.tetracom.atlas.tm.coref.uiac is the UIAC AR module which is reused by both summarizers. Additionally, we have integrated the Stanford Deterministic Coreference Resolution System in the com.tetracom.atlas.tm.coref.stanford plugin. For more information see http://www-nlp.stanford.edu/software/dcoref.shtml.
Additionally, we experimented with a third approach for coherent text summarization which combines the well-known LexRank algorithm (Erkan, Radev, 2004) with semantic graphs and word-sense disambiguation techniques (Palaza, Diaz, 2011). We have automatically built thesauri for the top-level domains in order to produce domain-focused extractive summaries. Finally, we apply clause-boundaries splitting in order to truncate the irrelevant or subordinating clauses in the sentences in the summary.The implementation of the summarization engine is in com.tetracom.atlas.tm.summary.lexrank plugin.
; return false;") |
; return false;") |
ATLAS (Applied Technology for Language-Aided CMS) is a project funded by the European Commission under the CIP ICT Policy Support Programme.